富士通のSecure Archiver
昨日知ったばかり。^^;富士通は、1998年2月16日付で 「世界初の電子化データの原本性保証文書管理システム・Secure Archiver」 を開発したと発表。
「原本性(authenticity)の保証」に重点があるようである。
概要:
- 製品はハードウェアの姿をしている(専用ボード+MOディスク)
- 専用ボードには「改竄検出用専用LSI」が搭載されているそうだ
- 登録時に識別情報を生成し、文書の一意性を保証
- 識別情報は文書の電子署名+serial番号+ Secure ArchiverのID+記憶媒体のIDより成る
- 原本と写しとの区別
- networkを通じて原本及び写しが転送できる。
- ここで、原本を移動した時は、時刻情報及び移動履歴が識別情報に付加される。
- 研究の動機/目的
- 電子文書の適切な管理は緊急の課題
- フローとしての電子情報だけではなく、 ストックとしての情報にも目を向けるべき
- 長期間にわたって電子的記録を適切に管理・保存するシステムの必要性
- フローとしての電子情報だけではなく、 ストックとしての情報にも目を向けるべき
- 「適正」→出所が正しく伝えられること(Authenticity)、 内容に改変が加えられないこと(Integrity)、 情報が保護されるべき時には保護されること(Confidentiality)
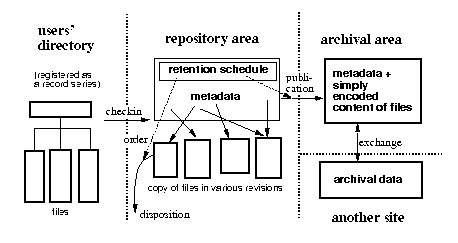
図1: 卒研1で提唱したシステムの概念図
- 前回(卒論)でやったことの反省と、今後の方針
- 前回は「文化」とか「歴史」といった辺りで少々肩肘張ってしまったが、
今回はもう少し醒めて行きたいと思う
- 前回は主に仕様を述べて、実装は殆んどやらなかった
- なんだか、表現形式がplain textであるというだけで、
恐ろしく効率の悪いRevision Control System兼Archiverを作ったに
過ぎないような気がする。
- Security系の充実を図りたい
- 今回は、権利関係がより複雑になるであろう私的な文書の管理についても challengeしてみようと思う。
- なるべくソフトの範囲内で話をつける指向性でいく
- システムにハード依存の部分はあるべきではないと考える。
- ハードウェア技術も無視できないのは事実なのだが。(例: RAID)
- 積極的にネットワークを利用する
- マルチメディアへの対応は、忘れたわけではないが、優先順位は低い
- 諸問題及びアイデア えらく話が分散しておりますが……。
要するに、まだまだ問題山積ということです。- (メタ)データ及びその構造
- ドキュメントの二次元モデル
- 文書の階層(directory)構造の次元 + 経時的変化の次元
- データ及びメタデータは、全てXMLによって記述
- これらの情報は自らOODBを成す(はず)
- ファイルの部分ごとにmetadata(更新履歴・所有者情報など)を記述できないか?
- 例えば、「ほげほげ」が、時刻somedayにanother@personによって
「ほげほにゃ」に書き換えられた場合、
のように記述する。ほげほげ
↓
ほげ <history> <original>ほげ</original>
<replaced date="someday" by="another@person"> ほにゃ</replaced>
</history>- ご利益→肌理の細かいaccess管理が可能になる、 文書の細分化された各部分について責任が明確化される
- 課題: 元から書いてある「ほげ」と 後から書き直した「ほげ」は 区別されるべきか?
- ご利益→肌理の細かいaccess管理が可能になる、 文書の細分化された各部分について責任が明確化される
- 他の文書へのリンク・annotationの扱い?
- URL腐敗(或いはそれに類するもの)への対策が必要
- コード系及びデータ形式の問題
- 扱われるデータの形式を問わないものにしたい
- テキストだけでもいろいろ、加えて画像などの諸形式
- →XMLは骨組みとしてだけ使用。 しかし、binary dataについてもSGML式の記述は有効なのか?
- 文字コードに関する問題
- 将来に亙るsoftwareの動作を保証する必要性
- ソースとまでは行かなくても、仕様書くらいは
どこかに保管するようにしたい。
- データをどう変換するかの規則を明確に定義すれば、 極端な話、ハードウェアがなくなっても大丈夫、と思うのだが……。
- データをどう変換するかの規則を明確に定義すれば、 極端な話、ハードウェアがなくなっても大丈夫、と思うのだが……。
- 情報の取捨選択
- それは必要か? 必要なら、それはどうやればいいのか?
- ここで必要なのは、「歴史的重要度」という観点から見た Information Filteringということになるのだろうが、 そんな高水準のfilterlingは果たして可能なのか?
- 卒論では「事前に決定したRetention Scheduleによる」としたが、 本当にそれでいいのか?
- # やはり、自動生成とかできたらすごいのだが。
- ネットワークを介した文書の転送
- ほぼ統一されたプロトコルを有する強み
- 容易に複製を持つことができ、また、 それによって文書の唯一性を克服することができる
- 応用例: 式年遷宮方式
- 容易に複製を持つことができ、また、 それによって文書の唯一性を克服することができる
- 図2を参照のこと。
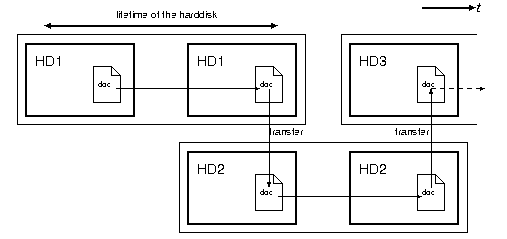
図2: 式年遷宮方式・概念図
- ほぼ統一されたプロトコルを有する強み
- Security Model(認証・信用系)
情報を滅失から保護するのもまたsecurityの問題と言えるであろう。- 利用者の種類と権限に関するモデルをどうするか?
- 誰を信用するか? そしてそれをどのように表現するか?
- → Hierarchicalモデル 対 信用の輪モデル(PGPが採用しているような)
- データの各部分は、情報の作成者、及び改変等の権限ある人の情報を持つべし
- 人に関する情報も、networkを利用する関係上、
全世界からnetwork越しに参照できる形式である必要があろう。
- 無論、file以下の単位についてこれらの情報を持てることが望ましい。
- 時間情報が重要になる
- 情報の抹消なり開示なりは時刻によってcontrolされるので、 (特に時系列に対して)動的なsecurity modelが必要になる。
- 索引・検索
一応計画には入っているのだが、まだあまりきちんと考えていない。
- todos(すべきこと)
とにかく基礎体力をつけないと。- Security関連の勉強
- さしあたり、sshをinstallするあたりから始めてみようと思います。
- XMLの勉強
- リンク構造の部は要注意と見た。
- toolのinstall:)
- 前回話だけして実装しなかった部分の実装作業
- 実装した部分も作り直し
-
本当にprototypeでしかなかったので。
- etc...
- 研究の動機/目的